Java NIO Buffer API
缓冲区(Buffer)是 NIO 的一个重要概念,所有的网络数据,都需要Buffer 封装一层再出去。
|
|
首先搞清楚上面的概念,尤其是 limit 和 capacity 是不一样的
It is very important to understand the difference between the limit and the capacity of the buffer. The capacity is the maximum number of items the buffer can contain; the limit is a value, somewhere between 0 and the capacity, representing an arbitrary limitation for the buffer set by using the limit or the flip methods.
flip()
|
|
flip 是人为给一个 buffer 的读取限制,这个限制就叫 limit,limit 这个值只能是在0和 capacity 之间,而capacity 是 allocation 时分配的物理限制,两者完全不一样。除此之外,flip还会将 position 设置为0。
例如,如果一个通道的 read()操作完成,而您想要查看被通道放入缓冲区内的数据,就需要调用 flip 操作,将其翻转。
clear()
这个方法的作用就是用来初始化缓存空间,把 position 重置为0,例如读取文件时将文件内容置入缓存时要先执行此方法。上文提到的 limit,也会在初始化过程中清理掉
|
|
rewind()
和 clear 类似,会把 position 重置为0,然而不会清掉 limit;
compact()
压缩。
一个capacity 为10的 ByteBuffer,假设已经读的位置为 position 5,如果此时调用 compact 方法,那么5之前的数据将会视为应该清理的垃圾数据,该算法会自动将5之后的有效数据(limit 之前)做一次拷贝,拷贝的起始地址为 ByteBuffer position 0,而此时 position 的位置为有效数据的最后一个,而 limit 则重设为 capacity。
mark() & reset()
标记。
在调用 mark 方法之前,Buffer 中是不存在标记的,对应的 reset 方法就是回到当前标记的 position,如果 当前不存在 mark,则会抛出异常 InvalidMarkException
equals() & compareTo()
equals 函数是用来判断两个缓冲区数据是否等价。
等价的充要条件:
- 两个 buffer 类型要相同;
- 两个 buffer 对象剩余相同数量的元素(position -> limit = 剩余元素);
- 剩余元素的顺序必须一致
compareTo
比较两个同类型 buffer 对象从 position 到两者最短 remaining数的值大小,如果是 ByteBuffer ,每个元素就按照 Byte 的compare 比较,从头到尾,比较出第一个不等于0的值即可返回。
duplicate()
复制缓冲区
slice()
与复制不同的是,slice 只从 position -> limit 截取,并复制生成一个新的缓冲区,这个新的缓冲区 capacity 仅仅是原有缓冲区的 limit 减去 position
字节顺序
先来理解什么是大端排序(Big-Endian),什么是小端排序(Big-Endian)
NUXI 问题
把 UN 和 IX 分别作为短整型存储(各2个字节)
- UNIX 在大端机存储是『UNIX』
- UNIX 在小端机存储则是『NUXI』
再比如一个整型存储的数据(4个字节)
大端机是这样存储: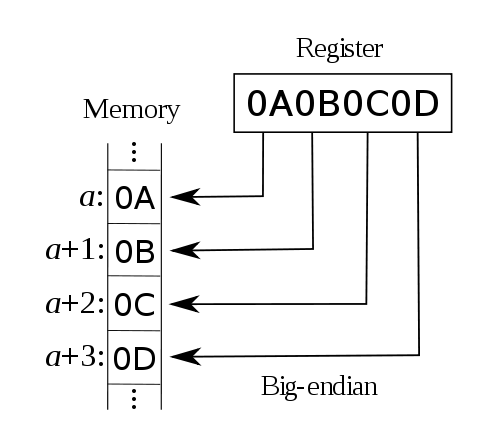
小端机是这样存储: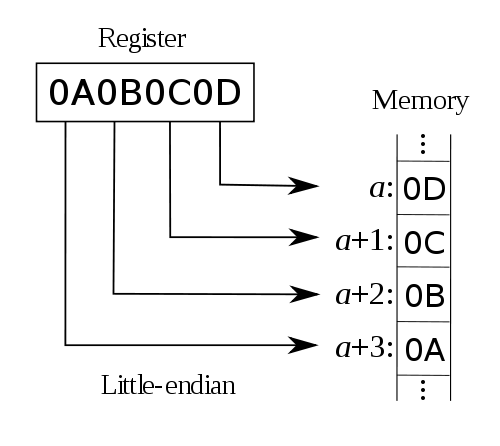
这会导致什么问题呢?
网络传输是默认大端排序的,而如果传输到了小端机上,那么小端机读到的数据将十分诡异了。
Java 可以通过 ByteBuffer.order()方法返回当前字节排序,并可以控制排序规则
直接缓冲区(Direct Buffer Memory)
- 能直接进行 I/O 交互的只有 ByteBuffer;
- 所有I/O操作都是从直接缓冲区读写数据;
- 直接缓冲区属于堆外内存,不属于 JVM 直接管辖的区域,操作系统直接管辖;
- ByteBuffer 如果分配在了堆内存里,那么在执行I/O 操作的时候,要多一步处理步骤,即把堆内存中的 Buffer 拷贝到直接缓冲区,因此直接缓冲区写入 Channel 的速度会更快;
- 通过 ByteBuffer.allocateDirect() 分配直接缓冲区
视图缓冲区
ByteBuffer 特有方法
- asCharBuffer()
- asLongBuffer()
- asIntBuffer()
- asShortBuffer()
- asFloatBuffer()
- asDoubleBuffer()
以limit 为上界,position 为期点,做切分(slice),获取出一个视图 Buffer。
之所以称之为视图,是因为其并非真正副本,而是与生成视图之前的 ByteBuffer 对应的是同一个内存区域。如果需要使之为副本,则要调用 slice 或 duplicate 方法
数据元素视图
获取数据元素方法很多,不一一列举,举个例子
getInt(): ByteBuffer 调用这个方法,就会从当前 position 往后取四个字节,根据字节排序规则,生成出具体的Int 类型的值,以 Int 类型展示。